Why Agentic AI Must Think in Cohorts, Not Individual Cases
.jpeg)


Agentic AI systems are evolving rapidly. What began as text generation is now becoming decision-making infrastructure: systems that plan, reason, and act across complex operational workflows.
But as these systems grow more capable, a fundamental question becomes unavoidable.
How should they evaluate their own decisions?
Most agentic systems evaluate each decision in isolation: one finding in, one verdict out. In security, that assumption breaks down fast. A security team triaging a cloud account faces hundreds of findings across VMs, containers, and managed services. These findings need to be prioritized collectively, because consistency in decisions and interrelated patterns only emerge when issues are evaluated in context. Yet today's AI agents have no mechanism to reason across issues.
The Standard Agentic Architecture Has a Structural Limitation
Most agentic frameworks today rely on a pattern that is conceptually clean but structurally limited.

A primary agent generates a response, an action, or a recommendation. A second agent, typically called a judge, evaluates whether that output is correct, safe, or useful. The judge provides feedback, the primary agent refines its reasoning, and the loop continues. This process, known formally as iterative self-refinement, is the backbone of self-correcting AI systems.
It works well when each input can be judged on its own merit i.e. when the correctness of one response has no bearing on another.
The problem emerges in domains where individual decisions are not independent. In those environments, evaluating each output in isolation is not just inefficient. It actively discards the most useful signal available. In security, this limitation becomes particularly acute. Findings are not independent: they share assets, infrastructure, and environmental context. Recognizing why requires a closer look at how security decisions actually relate to one another.
In Cybersecurity, Decisions Are Inherently Relational
Modern environments generate interrelated security findings, not isolated tickets. Vulnerabilities, misconfigurations, and exposure issues are woven together across assets, services, accounts, and network boundaries.
Let's take a concrete example. A distributed storage system is deployed across several worker nodes in a Kubernetes cluster. Each node carries a set of misconfigurations: permissive security contexts, host-path mounts, broad capabilities. Viewed independently, each node looks like a separate problem. But these misconfiguations stem from a shared operational cause (the storage system legitimately requires elevated privileges on worker nodes) and they are mitigated or exacerbated together. An agent that discovers the software genuinely needs certain privileges on one node should immediately carry that insight to the other nodes running the same software. Without joint evaluation, the system may reach inconsistent conclusions: accepting the configuration on one node while flagging the identical pattern as dangerous on another.
This is how experienced security analysts actually think. They do not audit one record and move to the next. They look across related findings, compare patterns, surface inconsistencies, and draw conclusions that only become visible at scale.
Consistency across an account matters just as much as accuracy on any single finding. Without a comparative view, the system cannot detect recurring environmental quirks, enforce uniform treatment of similar assets, or distinguish routine noise from a genuinely critical cluster of findings.
The challenge is that current agentic systems are not built this way. Judge agents evaluate each query-response pair as if it exists in a vacuum. Information does not flow across related triage issues. A hard-won insight from one finding has no mechanism to inform the review of the next.
The result is an evaluation process that is structurally incapable of reasoning about the relationships that matter most.
JAF: Joint Inference Across Related Decisions
In our latest paper, we introduce Judge Agent Forest (JAF) to address this gap directly.
Judge Agent Forest (JAF) is a framework in which the judge agent conducts joint inference across a cohort of query-response pairs generated by a primary agent, rather than evaluating each in isolation. Here, a cohort denotes a logically related collection of findings (for example, all open vulnerability issues for a tenant, account, or time window), not a mini-batch chosen for computational efficiency. This paradigm elevates the judge from a local evaluator to a holistic learner: by simultaneously assessing related responses, the judge discerns cross-instance patterns and inconsistencies, enabling the primary agent to improve by viewing its own outputs through the judge's collective perspective.
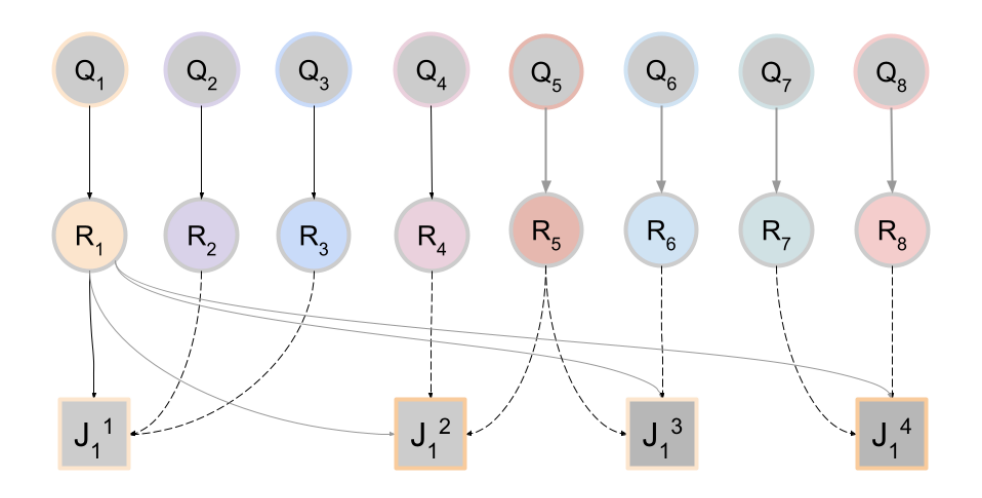
In practice, a judge's context window cannot hold an entire cohort of hundreds or thousands of findings. JAF solves this by giving each judge-call a small, randomized neighborhood: the focal finding plus a handful of relation-aware peers from the same cohort. Different judge calls see different subsets. This is the "Forest" in the name: like trees in a random forest, each judge invocation sees a different slice of the data, and the ensemble across invocations produces robust, consensus-driven verdicts.
With this structure, the judge is no longer asking only whether a single response is correct. It is comparing the focal response against its peers: is the reasoning consistent with related cases? Does the same logic hold across similar findings? Should a pattern visible across the neighborhood change the assessment of this particular finding?
These overlapping neighborhoods form a knowledge graph over the cohort: each finding is a node, and an edge connects two findings whenever they co-occur in a judge's context. When JAF runs iteratively, each round re-samples the neighborhoods. A correction discovered for one finding in round *t* reaches its neighbors immediately, and their neighbors in round *t+1*. Over a few rounds, knowledge propagates across the cohort, much like message-passing in belief propagation, gradually enforcing global consistency without any single judge-call needing to see the full picture.
JAF also subsumes prior uses of judges for iterative self-refinement and multi-chain-of-thought exploration. Rather than generating many reasoning paths per hard query in isolation, the system exploits the diversity of reasoning that already arises across the cohort: chains of thought produced for some findings become informative context for others, amortizing compute cost over an entire workload.

How JAF Selects the Right Peer Context
The quality of cohort-based judgment depends entirely on which peer examples the judge sees.
Naive retrieval in embedding space captures semantic similarity but misses the structure that matters in practice. Two vulnerabilities might be semantically similar in their descriptions while being unrelated from a risk perspective. Two that look dissimilar in text might share a critical asset, a deployment role, or a network segment that makes them closely related for triage purposes.
To address this, we developed a locality-sensitive hashing approach that integrates multiple signals simultaneously: semantic embeddings, LLM-derived hash predicates, categorical labels and metadata, and domain structure from the underlying environment (e.g., shared assets, network topology, or co-occurrence within a cohort). The result is an efficient, interpretable retrieval mechanism that selects peer examples based on the dimensions that actually matter for the task, not just textual proximity.
This makes JAF practical at scale. Cohort-based reasoning does not require reviewing every related finding. It requires surfacing the right ones.
Cloud Vulnerability Triage
Security analysis is inherently relational. A single vulnerability, misconfiguration, or exposed service may appear low risk in isolation but become critical when viewed alongside related findings across the same environment.
For example, a publicly exposed service might appear low risk on its own. But if that service runs with the same role or exists on the same network segment as other sensitive systems, the same finding must be evaluated differently. In isolation, it looks benign. In context, it needs to be assessed consistently with related issues.
Cloud vulnerability triage provides a natural proving ground for JAF. The task captures the full difficulty of agentic reasoning in security. Decisions require integrating structured signals like CVSS vectors or known exploits with broader environmental context. False negatives and false positives carry different operational costs. And triage is inherently cohort-based: the right prioritization for any single finding often depends on what is happening across the broader account.
These are not edge cases. They are the baseline conditions security teams operate under every day.
The empirical results support the central claim. Joint inference across related findings improves consistency and calibration in ways that instance-local evaluation cannot replicate. Patterns that are invisible in isolation become legible in context. The primary agent's outputs improve not just at the focal instance but across the cohort, because feedback propagates through the shared neighborhood structure.
This is what makes agentic AI reliable in high-stakes environments.
What This Means for Remediation Operations
The implications extend beyond vulnerability triage. Remediation Operations is defined by speed and consistency: how quickly teams can analyze findings, and how consistently they act on them across an environment.
As the average time-to-exploit has dropped from ~5 days to near zero, the window available to analysts shrinks while the cost of getting decisions wrong rises (source: Mandiant). At the same time, advances in AI-driven discovery, such as Claude Mythos, are rapidly increasing the volume of findings teams must process.
This creates a fundamental problem: decisions must be made quickly and applied consistently across thousands of related findings. Without a mechanism to reason across those relationships, teams produce inconsistent outcomes, repeat the same analysis, and miss patterns that indicate real risk.
Cohort-based judgment addresses this directly. By evaluating related findings together and propagating decisions across them, systems like JAF allow analysis performed once to inform many, enforcing consistency while keeping pace with the scale and speed of modern environments.
For example, if a misconfiguration is determined to be non-exploitable in one service given its context, that reasoning should apply to similar instances across the environment. Without shared evaluation, each is analyzed independently, leading to inconsistent outcomes and repeated work. Similarly, if an issue is identified as exploitable, that decision should propagate to related findings, allowing remediation efforts to be prioritized consistently across the environment.
In today’s environment, the bottleneck is no longer finding vulnerabilities. It is making the right decisions fast enough and applying them everywhere they matter.
Looking Ahead
Agentic AI evaluation is still in its early stages. The frameworks in use today were designed for simpler tasks and have been carried forward largely unchanged into more complex environments.
JAF is one step toward evaluation architectures that better reflect the structure of these problems.
The shift from instance-level judgment to cohort-level reasoning may appear simple, but it changes how consistency, reliability, and ultimately operational trust are enforced across related decisions.
Featured Blog Posts
Explore our latest blog posts on cybersecurity vulnerabilities.
.png)

Ready to Reduce Cloud Security Noise and Act Faster?
Discover the power of Averlon’s AI-driven insights. Identify and prioritize real threats faster and drive a swift, targeted response to regain control of your cloud. Shrink the time to resolution for critical risk by up to 90%.
